Information Retrieval (IR) is the activity of obtaining information from large collections of Information sources in response to a need.
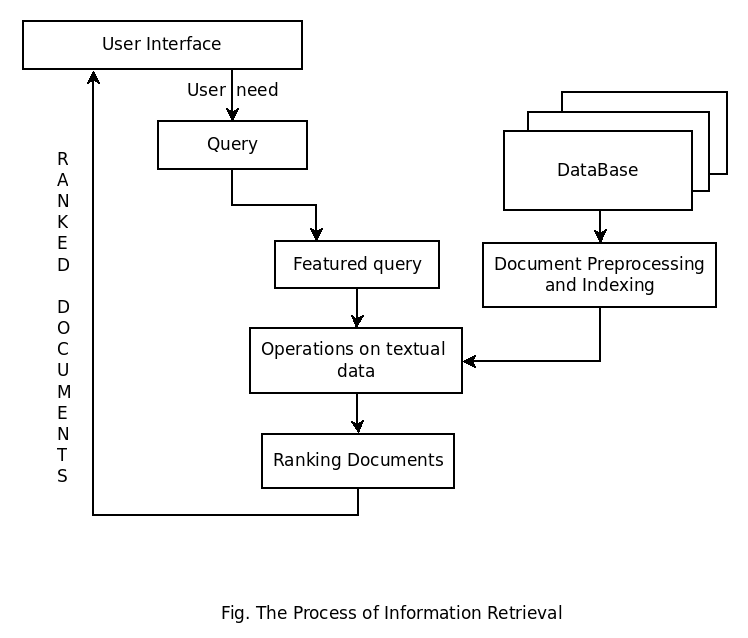
The working of Information Retrieval process is explained below
- The Process of Information Retrieval starts when a user creates any query into the system through some graphical interface provided.
- These user-defined queries are the statements of needed information. for example, queries fork by users in search engines.
- In IR single query does not match to the right data object instead it matches with the several collections of data objects from which the most relevant document is taken into consideration for further evaluation.
- The ranking of relevant documents is done to find out the most related document to the given query.
- This is the key difference between the Database searching and Information Retrieval.
- After the query is sent to the core of the system. This part has the access to the content management module which is directly linked with the back-end i.e. the large collections of data objects.
- Once results R are generated by the core system then it is returned to the user by some graphical user interfaces.
- The process repeats and results are modified until the user satisfied for what he is actually looking for.
The Following figure sketches processing of textual queries performed by
an Information Retrieval system.
The Operations on Textual data of documents are illustrated in the figure below ->
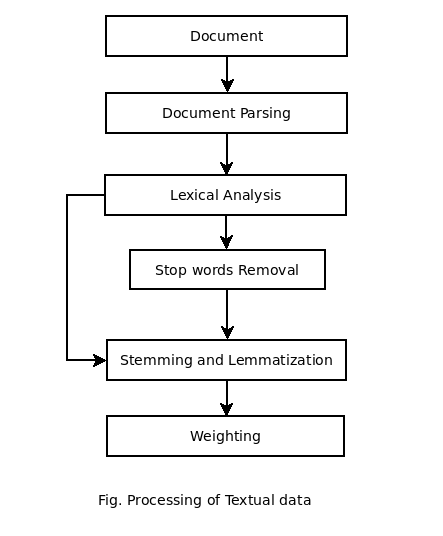 Above figure sketches the Processing of textual data typically performed by Information Retrieval engine, by taking a document as input and yielding its index terms.
Above figure sketches the Processing of textual data typically performed by Information Retrieval engine, by taking a document as input and yielding its index terms.
1. Document Parsing
The Documents comes from different source combinations such as multiple languages, formattings, character sets; normally, if any document consisting of more than languages. e.g. Consider a Spanish mail which has some part in french language.
Thus Document parsing deals with the overall document structure. In this phase, it breaks down the document into discrete components. In Preprocessing phase it creates unit documents for example one document representing emails and another as additional specific part.
2. Lexical Analysis
In Lexical analysis, tokenization is the process of breaking a stream into words, phrases, symbols, or other meaningful terms called tokens. These meaningful elements ae further sent to Parts of Speech Tagging.
Typically, Tokenization occurs at a word level.
3. Stemming and Lemmatization
In English grammar, for correct sentence structures, we often use different forms of any word. e.g. go, going, goes etc. Stemming is the process of cutting down the affixes and let the root word be found out. Any word is formed using regular noun + plural affix. check more on A Cognitive study of Lexicons – by Shirish Kadam
Lemmatization usually refers to doing these things properly with Vocabulary and Morphological analysis of words. Aiming to remove inflectional endings only.
Further Reading :

Reblogged this on SHIRISH KADAM.
Thanks a lot 😊
Find same post on my Blogger http://amitgunjal.blogspot.in/2016/11/the-process-of-information-retrieval-or.html
Can You please explain role of parsing in information retrieval in nlp?
you may not see this but this helpss me soooo much in understanding IR. i studied it but it’s scattered and i dont understand anything except for knowing the terms. unfortunately I failed to understand what they are for. but this helps me a lot in gathering the pieces. i couldnt thank you enough